


Next: model1
Up: 日英統計翻訳システム
Previous: -gramモデル
目次
統計翻訳における単語対応を獲得するための代表的なモデルとして,IBMのBrownらによる仏英翻訳モデル[2]がある.
IBM翻訳モデルは,model1からmodel5までの5つのモデルから構成されている.各モデルの概要を以下に示す.
- model1
- 目的言語のある単語が原言語の単語に訳される確率を用いる
- model2
- model1に加えて,目的言語のある単語に対応する原言語の単語の原言語文中での位置の確率(以下,permutation確率と呼ぶ)を用いる(絶対位置)
- model3
- model2に加えて,目的言語のある単語が原言語の何単語に対応するかの確率を用いる
- model4
- model3のpermutation確率を改良(相対位置)
- model5
- model4のpermutation確率を更に改良
IBM翻訳モデルは仏英翻訳を前提としているが,本研究では日英翻訳を扱っているため,日英翻訳を前提に説明する.なお,以下の説明は藤原ら[10]の論文より引用した.
原言語の日本語文を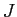 ,目的言語の英語文を
,目的言語の英語文を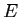 として定義する.IBM翻訳モデルにおいて,日本語文と英語文の翻訳モデル
として定義する.IBM翻訳モデルにおいて,日本語文と英語文の翻訳モデル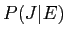 を計算するため,アライメント
を計算するため,アライメント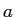 を用いる.以下にIBMモデルの基本的な計算式を示す.
を用いる.以下にIBMモデルの基本的な計算式を示す.
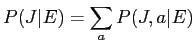 |
|
|
(7) |
ここで,アライメント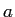 は,との単語の対応を意味している.
IBM翻訳モデルにおいて,各日単語に対応する英単語は1つであるのに対して,各英単語に対応する日単語は0からn個あると仮定する.また,日単語と適切な英単語が対応しない場合,英語文の先頭に
は,との単語の対応を意味している.
IBM翻訳モデルにおいて,各日単語に対応する英単語は1つであるのに対して,各英単語に対応する日単語は0からn個あると仮定する.また,日単語と適切な英単語が対応しない場合,英語文の先頭に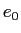 という空単語があると仮定し,日単語と対応させる.
という空単語があると仮定し,日単語と対応させる.
Subsections
s122019
2016-03-03