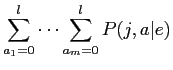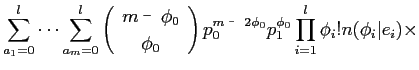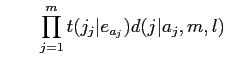


Next: model4
Up: 単語に基づく翻訳モデル
Previous: model2
目次
model1およびmodel2において,日単語と英単語の対応は1対1の場合のみを考慮していた.
しかし,model3では,1つの単語が複数の単語に対応する場合や,単語の翻訳位置の距離についても考慮する.
また,モデル3では単語の位置を絶対位置として考えている.モデル3では以下のパラメータを用いる.
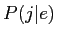
英単語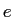 が日単語
が日単語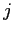 に翻訳される確率
に翻訳される確率
-
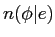
英単語が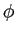 個の日単語と対応する確率
個の日単語と対応する確率
-
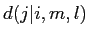
英語文の長さ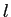 ,日本語文の長さ
,日本語文の長さ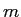 のとき,
のとき,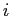 番目の英単語
番目の英単語
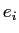 が番目の日単語
が番目の日単語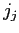 に翻訳される確率
に翻訳される確率
さらに,英単語に翻訳されない日本語の単語数を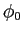 として,そのような単語が発生する確率
として,そのような単語が発生する確率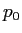 を以下の式に表す.
を以下の式に表す.
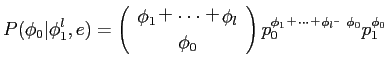 |
|
|
(21) |
したがって,model3は以下の式によって表される.
モデル3では,全ての単語対応を考慮して計算するため,計算量が膨大となる.そのため,期待値は近似によって求められる.
s122019
2016-03-03