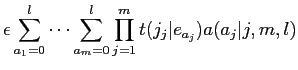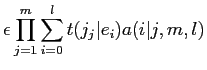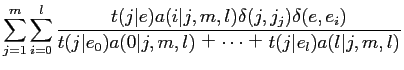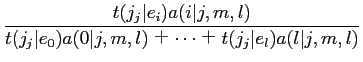


Next: model3
Up: 単語に基づく翻訳モデル
Previous: model1
目次
model1において,アライメントの確率は英語文の長さ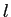 にのみ依存する.
そこでmodel2では,英語文の長さに加え,
にのみ依存する.
そこでmodel2では,英語文の長さに加え,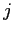 単語目のアライメント
単語目のアライメント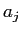 ,
日本語文の長さ
,
日本語文の長さ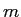 に依存するとし,以下の式で表す.
に依存するとし,以下の式で表す.
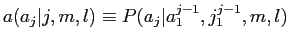 |
|
|
(16) |
よって,model1の式(6)は以下のように置き換えられる.
model2において,対訳文中の英単語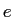 と日単語が対応付けされる回数の期待値である
と日単語が対応付けされる回数の期待値である
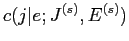 と,日単語の位置と英単語の位置
と,日単語の位置と英単語の位置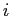 が対応付けられる回数の期待値
が対応付けられる回数の期待値
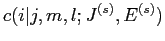 が存在する.以下に,期待値
と
を求める式を示す.
が存在する.以下に,期待値
と
を求める式を示す.
model2においても,最適解を推定するためにEMアルゴリズムを用いる.しかし,計算によって複数の極大値が算出され,最適解が
得られない場合が存在する.model2の特殊な場合に,
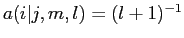 が挙げられるが,これはmodel1として考えることができる.また,最適解が保証されているmodel1で求められた値を初期値として用いることで,最適解を求めることができる.
が挙げられるが,これはmodel1として考えることができる.また,最適解が保証されているmodel1で求められた値を初期値として用いることで,最適解を求めることができる.
s122019
2016-03-03