IBM翻訳モデルを以下に示す.これは, 力久ら[8]の抜粋である.統計翻訳の代表的なモデルとして, IBMのBrownらによる仏英翻訳モデルがある.IMB翻訳モデルは, 単語に基づく統計翻訳を想定して作成された, 単語対応の確率モデルである.この翻訳モデルは順に複雑な計算を行うモデル1から5の5つのモデルで構成される.
本章では.原言語であるフランス語文を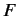 , 目的言語である英語文を
, 目的言語である英語文を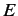 として定義する.
として定義する.
IBMモデルでは, フランス語文, 英語文の翻訳モデル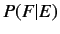 を計算する
ために, アライメント
を計算する
ために, アライメント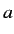 を用いる.以下にIBMモデルの基本式を示す.
を用いる.以下にIBMモデルの基本式を示す.
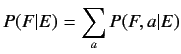 |
|
|
(2.1) |
アライメントとは仏単語と英単語の対応を意味している.IBMモデルのアライメ
ントでは, 各仏単語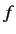 に対応する英単語
に対応する英単語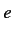 は1つあり, 各英単語に対
応する仏単語は0からn個ある.また仏単語において適切な英単語と
対応しない場合, 英語文の先頭に空単語
は1つあり, 各英単語に対
応する仏単語は0からn個ある.また仏単語において適切な英単語と
対応しない場合, 英語文の先頭に空単語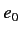 があると仮定し, その仏NMT 参考文献単語
と空単語を対応づける.
があると仮定し, その仏NMT 参考文献単語
と空単語を対応づける.
Subsections