


Next: 言語モデル
Up: 日英統計翻訳
Previous: 概要
目次
句に基づく統計翻訳は句対応の翻訳モデルを用いる.また,原言語文を目的言語文に翻訳する場合に,隣接する複数の単語を用いて翻訳を行う.本研究では日英翻訳を行うため,日英統計翻訳を説明する.
日英統計翻訳では,日本語文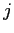 を入力文とした場合,翻訳モデル
を入力文とした場合,翻訳モデル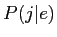 と言語モデル
と言語モデル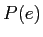 の全ての組み合わせから,確率が最大となる英語文
の全ての組み合わせから,確率が最大となる英語文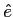 を探索し,出力文とする.
を探索し,出力文とする.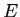 を探索する翻訳器をデコーダと呼ぶ.以下に基本的なモデルを示す.また,日英統計翻訳の流れを図2.1に示す.
を探索する翻訳器をデコーダと呼ぶ.以下に基本的なモデルを示す.また,日英統計翻訳の流れを図2.1に示す.
ここで,が単語の場合は``単語に基づく翻訳翻訳"のモデル,が句の場合は``句に基づく統計翻訳"のモデルとなる.
s122019
2018-02-15
![\includegraphics[width=130mm]{SMTmethod.eps}](img11.png)