

Next: IBM翻訳モデル
Up: 日英統計翻訳
Previous: 句に基づく統計翻訳
目次
言語モデルは,単語列の生成確率を付与するモデルである.日英翻訳では,翻訳モデルを用いて生成された翻訳候補から,英語として自然な文を選出するために用いる.統計翻訳では一般的に,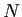 -gram モデルを用いる.-gramモデルとは``単語列
-gram モデルを用いる.-gramモデルとは``単語列
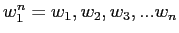 の
の 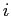 番目の単語
番目の単語 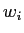 の生起確率
の生起確率 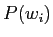 は直前の(
は直前の(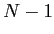 )の単語列
)の単語列
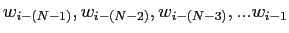 に依存する''という仮説に基づくモデルである.単語列
に依存する''という仮説に基づくモデルである.単語列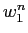 の生起確率
の生起確率 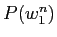 の計算式を以下に示す.
の計算式を以下に示す.
また,
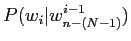 は以下の式で計算される.ここで
は以下の式で計算される.ここで 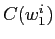 は単語列
は単語列 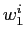 が出現する頻度を表す.
が出現する頻度を表す.
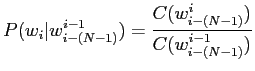 |
|
|
(2.6) |
s122019
2018-02-15