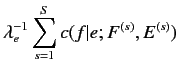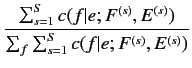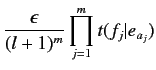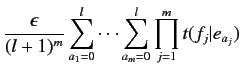Next: ・モデル2
Up: IBM翻訳モデル
Previous: IBM翻訳モデル
目次
(2.1)式は以下の式に分解することができる.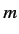 はフランス語文の長
さ,
はフランス語文の長
さ, 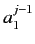 はフランス語文における, 1番目から
はフランス語文における, 1番目から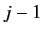 番目までのアラ
イメント,
番目までのアラ
イメント, 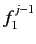 はフランス語文における, 1番目から
番目まで
単語を表している.
はフランス語文における, 1番目から
番目まで
単語を表している.
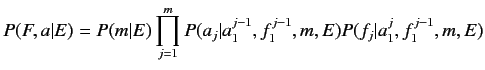 |
|
|
(2.2) |
(2.2)式ではとても複雑であるので計算が困難である.そこで, モデル1
では以下の仮定により, パラメータの簡略化を行う.
パラメータの簡略化を行うことで, 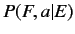 と
と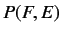 は以下の式で表
される.
は以下の式で表
される.
モデル1では翻訳確率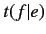 の初期値が0以外の場合,
Expectation-Maximization(EM)アルゴリズムを繰り返し行うことで得られる期待
値を用いて最適解を推定する.EMアルゴリズムの手順を以下に示す.
の初期値が0以外の場合,
Expectation-Maximization(EM)アルゴリズムを繰り返し行うことで得られる期待
値を用いて最適解を推定する.EMアルゴリズムの手順を以下に示す.
- 手順1
- 翻訳確率
の初期値を設定する.
- 手順2
- 仏英対訳対
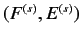 (但し,
(但し,
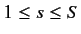 )において, 仏単語
)において, 仏単語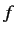 と英単語
と英単語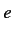 が対応する回数の期待値を以下の式により計算する.
が対応する回数の期待値を以下の式により計算する.
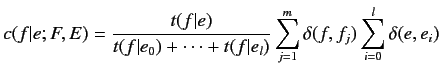 |
|
|
(2.6) |
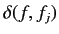 はフランス語文
はフランス語文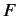 中で仏単語
が出現する回数,
中で仏単語
が出現する回数,
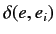 は英語文
は英語文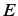 中で英単語
が出現する回数を表している.
中で英単語
が出現する回数を表している.
- 手順3
- 英語文
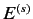 の中で1回以上出現する英単語
に対して, 翻訳確率
を計算する.
の中で1回以上出現する英単語
に対して, 翻訳確率
を計算する.
- 定数
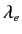 を以下の式により計算する.
を以下の式により計算する.
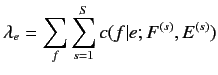 |
|
|
(2.7) |
- (2.7)式より求めた
を用いて, 翻訳確率
を再計算する.
- 手順4
- 翻訳確率
が収束するまで手順2と手順3を繰り返す.
Next: ・モデル2
Up: IBM翻訳モデル
Previous: IBM翻訳モデル
目次
2020-03-11