シルエット分析[7]は,クラスタ内のデータの凝集性とクラスタ間の離散性に基づく指標である.
シルエット分析では,クラスタ数ごとに,全てのデータのシルエット係数を計算し,この平均値が最大となるときのクラスタ数を選択する.
データ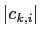 のシルエット係数
のシルエット係数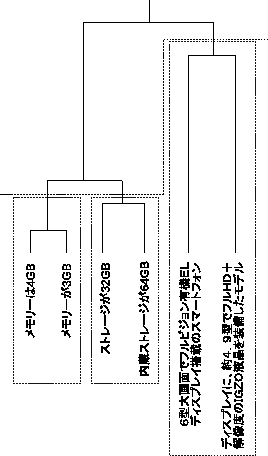 は式5.1で表される.
ここで,
は式5.1で表される.
ここで,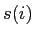 はデータとデータの属するクラスタに含まれる各データとの距離の平均,
はデータとデータの属するクラスタに含まれる各データとの距離の平均,
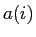 はデータの属さないクラスタのうち,データと最も距離の近いクラスタに含まれる各データとデータとの距離の平均を表す.
ここで,データと最も距離の近いクラスタは,データとクラスタに含まれる各データとの距離の平均が最小となる場合のクラスタである.
また,
はデータの属さないクラスタのうち,データと最も距離の近いクラスタに含まれる各データとデータとの距離の平均を表す.
ここで,データと最も距離の近いクラスタは,データとクラスタに含まれる各データとの距離の平均が最小となる場合のクラスタである.
また,
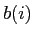 はとのうち,大きい方の値を表す.
はとのうち,大きい方の値を表す.
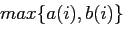 |
(5.1) |