| (2.2) |
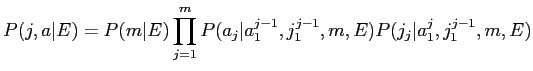 は日本語文の文長を示す.また,
は日本語文の文長を示す.また,
![]() は日本語文の1単語目から
は日本語文の1単語目から![]() -1単語目までのアライメントである.
そして
-1単語目までのアライメントである.
そして
![]() は日本語文の1番目から
は日本語文の1番目から![]() -1番目までの単語を示す.
ここで,Model1では以下を仮定している.
-1番目までの単語を示す.
ここで,Model1では以下を仮定している.
と
以上の仮定を用いて,式(4)は簡略化することができる.以下に式を示す.
| (2.3) | |||
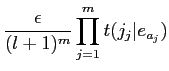 |
(2.4) | ||
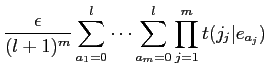 |
(2.5) |
Model1において,翻訳確率
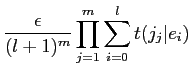 の初期値が0でない場合, EMアルゴリズムを用いて最適解を推定する.EMアルゴリズムの手順を以下に示す.
の初期値が0でない場合, EMアルゴリズムを用いて最適解を推定する.EMアルゴリズムの手順を以下に示す.
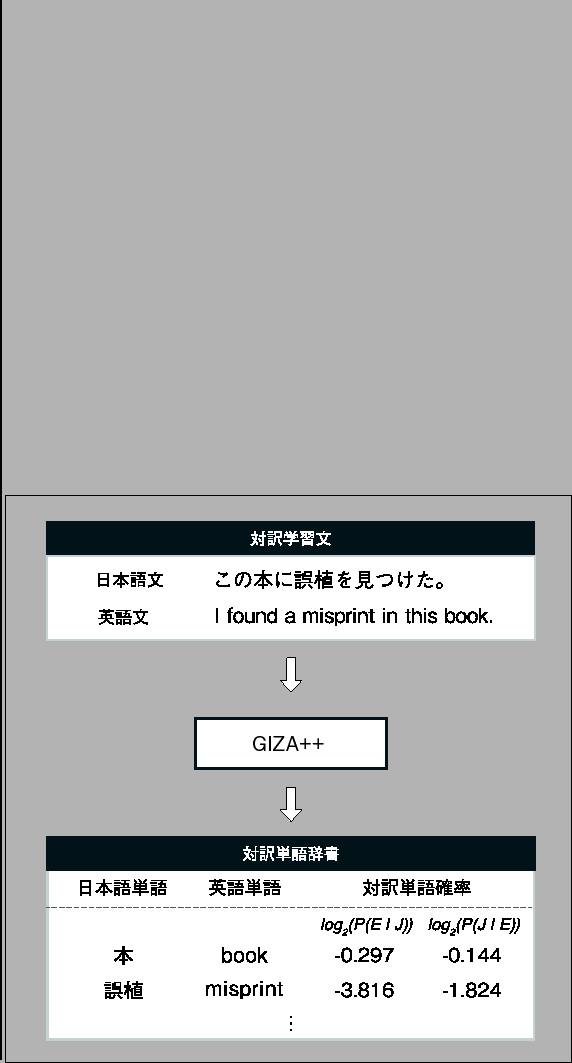 において日単語
において日単語| (2.6) |
を計算する.
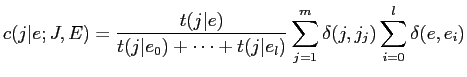 を以下の式で計算する
を以下の式で計算する
| (2.7) |
を用いて
を以下の式で再計算する
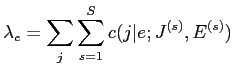 |
(2.8) | ||
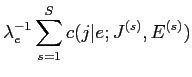 |
(2.9) |