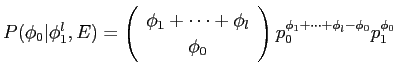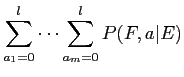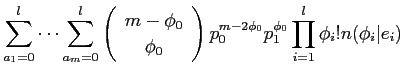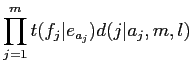さらに,英単語が仏単語に翻訳されない個数をとし,その確率 を以下の式で求める.このとき,歪み確率は で, で,は0より大きいとする.
したがって,モデル3は以下の式で求められる.
モデル3では,全てのアライメントを計算するため,計算量が膨大となるので期待値を 近似により求める.