


Next: 言語モデル
Up: 日英統計翻訳システム
Previous: 日英統計翻訳システム
目次
統計翻訳において,「単語に基づく統計翻訳」と,「句に基づく統計翻訳」がある.
初期の統計翻訳は,単語に基づく統計翻訳であった.しかし,近年提案された句に基づく統計翻訳[1]は,語順の並び替えや文脈における訳語の選択や翻訳精度において,単語に基づく統計翻訳よりも優れている.そのため,現在は句に基づく統計翻訳が主流となっている.したがって,本研究では,統計翻訳システムにおいて,句に基づく統計翻訳を用いる.
日英統計翻訳では,日本語文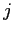 を入力文とした場合,翻訳モデル
を入力文とした場合,翻訳モデル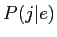 と言語モデル
と言語モデル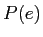 の全ての組み合わせから,確率が最大となる英語文
の全ての組み合わせから,確率が最大となる英語文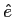 を探索し,出力文とする.
を探索し,出力文とする.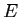 を探索する翻訳システムをデコーダと呼ぶ.以下に基本的なモデルを示す.また,日英統計翻訳の流れを図
を探索する翻訳システムをデコーダと呼ぶ.以下に基本的なモデルを示す.また,日英統計翻訳の流れを図![[*]](crossref.png) に示す.
に示す.
s122019
2016-03-03