


Next: 句に基づく翻訳モデル
Up: 日英統計翻訳システム
Previous: model5
目次
GIZA++[3]とは,日英方向と英日方向の対訳文から最尤な単語対応を得るための計算を行うツールである.
IBM翻訳モデルのmodel1からmodel5に基づいて,単語の対応関係の確率値を計算する.
GIZA++を用いた場合,以下の2つのファイルが出力される.
- 1. T TABLE (Translation Table)
- T TABLEは,Model1からModel3により作成された翻訳確率
 のデータである.
のデータである.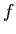 は翻訳する言語で,
は翻訳する言語で,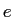 は目的言語である.T TABLEは各行が,目的言語の単語ID(
は目的言語である.T TABLEは各行が,目的言語の単語ID(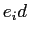 ),翻訳する言語の単語ID(
),翻訳する言語の単語ID(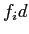 ),翻訳する言語の単語から目的言語の単語へ翻訳する確率(
),翻訳する言語の単語から目的言語の単語へ翻訳する確率(
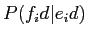 )で構成される.
)で構成される.
- 2. N TABLE (Fertility Table)
- N TABLEは,目的言語の単語における繁殖数を表したデータである.N TABLEは各行が,目的言語の単語ID(),繁殖数が0である確率(
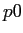 ),繁殖数が1である確率(
),繁殖数が1である確率(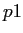 ),…,繁殖数がnである確率(
),…,繁殖数がnである確率(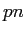 )で構成される.
)で構成される.
s122019
2016-03-03