意味属性による解析では以下の手順で係り先を決定する.
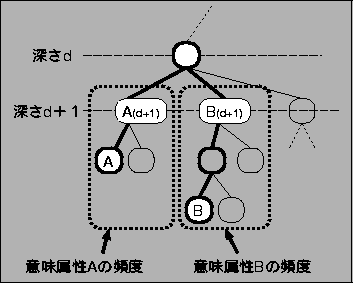
ここで,頻度統計がスパースになることを考慮して,以下の通りに頻度を計算す る.意味属性体系上の意味属性A,意味属性Bの共通の親ノード(深さd)を基準 にして,その子ノード(深さd+n)のうち,意味属性Aと意味属性Bを配下に属す る意味属性ノードの共起頻度の和をそれぞれ意味属性Aと意味属性Bの頻度とする (図2参照).
さらに,形容詞は直後の語に係る割合が多いことを考慮して,形容詞の直近の語に
優先度を与える.具体的には優先度を重みt(![]() 1)で表し,意味属性Bの頻度
が意味属性Aの頻度のt倍以上ある場合のみ係り先をBとし,正解率が最大になる
ようにtを定める.
1)で表し,意味属性Bの頻度
が意味属性Aの頻度のt倍以上ある場合のみ係り先をBとし,正解率が最大になる
ようにtを定める.