


Next: 必要最小限の意味属性の決定法
Up: ベクトル空間法
Previous: 従来のベクトル空間法
従来の単語を基底とする場合では、同義語、類議語が含む文書でも、表記が異なると類性が評価されないため、検索漏れが発生する。
この問題を解決するために、本論文では、特性ベクトルの基底を単語から単語の意味に置き換えたベクトル空間法を提案する。
本方式では、文書の特性ベクトル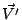 (式3)の基底は日本語名詞の意味的用法を2,710種に分類し、相互の意味的関係を最大12段の木構造で表現している日本語語彙大系[3]の一般名詞意味属性とし、各要素は各意味属性Siの重みsiを与える。
(式3)の基底は日本語名詞の意味的用法を2,710種に分類し、相互の意味的関係を最大12段の木構造で表現している日本語語彙大系[3]の一般名詞意味属性とし、各要素は各意味属性Siの重みsiを与える。
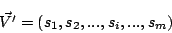 |
(3) |
また、重みsiの与え方(式4)として、一般的な
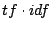 法を採用する。
法を採用する。
 |
|
|
(4) |
| TFi:意味属性Siに属する単語の文書内出現頻度 |
|
|
|
| DFi:意味属性Siに属する単語の出現する文書数 |
|
|
|
なお、以下では、単語を基底とするベクトル空間法を単語ベクトル空間法、意味属性を基底とするベクトル空間法を意味ベクトル空間法と呼ぶ。
2000-05-30