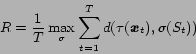Even though the optimal state sequence is obtained using forward decoding or Viterbi decoding, the relation between the classification and the speaker is still unknown. Therefore, we calculated the classification rate by the following expression.
In the above, ![]() is the optimal state sequence.
is the optimal state sequence. ![]() is an arbitrary
permutation of
is an arbitrary
permutation of
![]() , and
, and ![]() is the correct speaker of the
utterance.
is the correct speaker of the
utterance. ![]() is the variable that takes value 1 if the values agree,
and 0 if otherwise.
is the variable that takes value 1 if the values agree,
and 0 if otherwise.
In this study, the classification numbers are related to ![]() , the
correct classification rate is calculated for each of
, the
correct classification rate is calculated for each of ![]() permutations, and the maximum is defined as the
classification rate. Consequently, in the case of 4 speakers,
permutations, and the maximum is defined as the
classification rate. Consequently, in the case of 4 speakers,
![]() combinations are examined.
combinations are examined.