本節は中村[9]らの抜粋である.
句に基づく統計翻訳は句対応の翻訳モデルを用いる. 原言語文を目的言語文に翻訳する場合に,隣接する複数の単語(フレーズ)を用いて翻訳を行う方法である.本研究では日英方向の翻訳を行うため, 日英統計翻訳を説明する.日英統計翻訳システムの枠組みを図2.1に示す.
ここで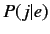 は翻訳モデル,
は翻訳モデル, 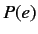 は言語モデルを示す.が単語であれば“単語に基づく統計翻訳”のモデル, が句であれば, “句に基づく統計翻訳”のモデルとなる.
は言語モデルを示す.が単語であれば“単語に基づく統計翻訳”のモデル, が句であれば, “句に基づく統計翻訳”のモデルとなる.
また, 学習データとは対訳文(英語文と日本語文の対)を大量に用意したものである. 学習データに含まれる各々のデータから, 翻訳モデルと言語モデルを学習する.
Subsections
![\includegraphics[width=13cm]{picture/fig2.eps}](img88.png)