文のベクトルの計算で用いる単語のベクトルは,FastText[6]の学習によって求める.
FastTextは隠れ層と出力層からなる2層のニューラルネットワークで,隠れ層が単語の分散表現に相当する.
FastText の学習データとして,Wikipediaの全1,061,375記事を用いた.
なお学習データは図4.1のように,日本語は全角,アルファベットと数字は半角に統一し,MeCab で形態素単位に分かち書きしている.
FastText の学習で用いたパラメータは,学習モデルをskip-gram,ベクトルの次元数を300とした.他のパラメータ値はデフォルト値を用いた.
図:
学習データの例
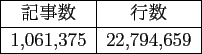 |
