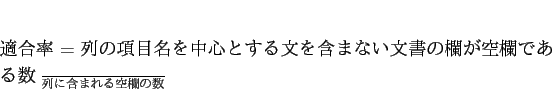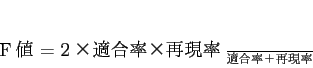提案手法によって作成した表から重要情報を書き漏らしている文書を見つけ,書き漏らしていることを指摘することで,文書作成を支援することができると考えられる.
例えば,文書3に重量に関する情報がない場合,作成された表が表1であれば,文書3の欄が空欄となっているので正しく書き漏らしを検出できている.一方,表2のような表が作成された場合は,文書3の欄に重量とは関係のない情報が含まれており,書き漏らしの検出を誤っている.また,表3のような表が作成された場合は,本来,重量の情報を含むはずの文書2の欄が空欄となっているので,書き漏らしの検出を誤っている. 書き漏らし箇所の検出の精度3から求める.F値が大きいほど,書き漏らし箇所を正しく検出できたことを意味する.5.1節の結果の表の重要度の高い上位5列に対する評価結果を表4に示す. また,無作為に抽出した5列での結果を表5に示す. 結果から,本来,空欄でない箇所まで空欄となっていることが多かった.この問題を解消するには,6.1節と同様に,共通の情報を含む文が異なるクラスタに割り当てられることを抑える必要がある.