


�$B �$B%U%l!<%:%F!<%V%k$N:n@.J}K!�(B
�$B>e$X�(B: �$BK]Lu%b%G%k�(B
�$BLa$k�(B: Model5
�$BL\
GIZA++[5]�$B$H$O!$E}7WK]Lu$KMQ$$$k$?$a$NC18l$N3NN(CM$r7W;;$9$k%D!<%k$G$"$k!%�(B
IBM�$B%b%G%k$N�(BModel1�$B!A�(B5�$B$rMQ$$$F!$K]Lu$9$k8@8l$HL\E*8@8l$K$*$1$kC18l$NBP1~4X78$N3NN(CM$r7W;;$9$k!%�(BGIZA++�$B$rMQ$$$?>l9g!$0J2<$N%U%!%$%k$,=PNO$5$l$k!%�(B
- T TABLE (Translation Table)
T TABLE�$B$O!$�(BModel1�$B$+$i�(BModel3�$B$K$h$j:n@.$5$l$?K]Lu3NN(�(B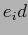 �$B$N%G!<%?$G$"$k!%�(B
�$B$N%G!<%?$G$"$k!%�(B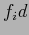 �$B$OK]Lu$9$k8@8l$G!$�(B
�$B$OK]Lu$9$k8@8l$G!$�(B �$B$OL\E*8@8l$G$"$k!%�(BT TABLE�$B$O3F9T$,!$L\E*8@8l$NC18l�(BID(
�$B$OL\E*8@8l$G$"$k!%�(BT TABLE�$B$O3F9T$,!$L\E*8@8l$NC18l�(BID(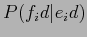 )�$B!$K]Lu$9$k8@8l$NC18l�(BID(
)�$B!$K]Lu$9$k8@8l$NC18l�(BID(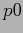 )�$B!$K]Lu$9$k8@8l$NC18l$+$iL\E*8@8l$NC18l$XK]Lu$9$k3NN(�(B(
)�$B!$K]Lu$9$k8@8l$NC18l$+$iL\E*8@8l$NC18l$XK]Lu$9$k3NN(�(B(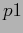 )�$B$G9=@.$5$l$k!%�(B
)�$B$G9=@.$5$l$k!%�(B
- N TABLE (Fertility Table)
N TABLE�$B$O!$L\E*8@8l$NC18l$K$*$1$kHK?#?t$rI=$7$?%G!<%?$G$"$k!%�(BN TABLE�$B$O3F9T$,!$L\E*8@8l$NC18l�(BID()�$B!$HK?#?t$,�(B0�$B$G$"$k3NN(�(B(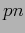 )�$B!$HK?#?t$,�(B1�$B$G$"$k3NN(�(B(
)�$B!$HK?#?t$,�(B1�$B$G$"$k3NN(�(B(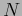 )�$B!$!D!$HK?#?t$,�(Bn�$B$G$"$k3NN(�(B(
)�$B!$!D!$HK?#?t$,�(Bn�$B$G$"$k3NN(�(B(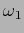 )�$B$G9=@.$5$l$k!%�(B
)�$B$G9=@.$5$l$k!%�(B
s102025
�$BJ?@.�(B27�$BG/�(B3�$B7n�(B9�$BF|�(B