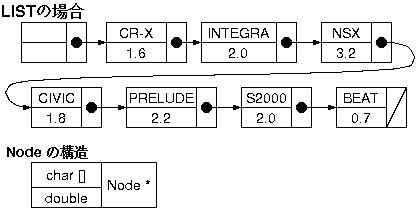
キーワードに値を対応づけて、データを管理する方法を連想記憶という。
(例) 自動車の名前と排気量の関係 CIVIC 1.8 S2000 2.0
キーワードと値をメンバ変数とする構造体を作り、線型リストに格納する方法がある。
検索キーワードを、リストの先頭からノードのキーワードと比較して、一致するところの値を出力することで、実現できる。
リストの後半のものを検索するには、そこまでのノード数だけ文字列比較(strncmp)を実行するので、効率が悪い。
キーワード(文字列)と値(double)をメンバ変数とする構造体を定義し、線型リストを操作する関数一式を作成せよ。雛型を以下に示すので、不足を補うこと。
関数 list_set は、キーワードが既に存在している場合は、値のみの書き換えを行い、新規のキーワードの場合は、push を行なう。例えば、list_set(&head,"NSX",3.0)の実行後に list_set(&head,"NSX",3.2) を実行すると、NSX のノードの 3.0 が 3.2 に書き換わる。
キーワードから簡単な計算で、インデックスを求めることにして、インデックスごとに線型リストを作る。
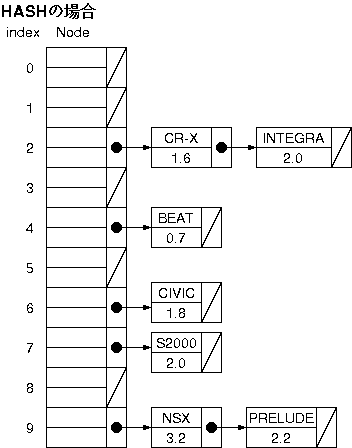
単純な線型リストは1本で長いものだったが、この方法では、それがバラバラ(ハッシュ)になっている。そこでこの手法をハッシュ法という。
ハッシュ法でにおいて、文字列からインデックスを求めるときに重要な点は、低コストでインッデックスが求まること、である。文字列毎にユニークなインデックスが求まらなくてもよいが、できるだけ、ユニークなほうがよい。
前のセクションで説明したリストの場合、検索キー「BEAT」に対応する値「0.7」を求めるために、リストの先頭から順に、ノードの文字列がキーと一致するかの文字列比較を7回する必要があった。
ハッシュの場合、「BEAT」のINDEXを計算すると、「BEAT」という文字列からINDEXの4を得るために、1回のコスト、そして、INDEX=4 のキーワード付き線型リストの先頭から検索する際に 1回のコストがかかるので、この場合、コスト=2で検索できる。
キーワード(文字列)からインデックスを計算する方法は何とおりもある。効率は悪いがわかりやすく説明をするために、ここでは、キーワードの文字コードの総和をインデックスの上限で割った余りを使うことにする。
次のプログラムを実行し、キーワードとインデックスの関係を図と比較せよ。 ⇒ list1002.c
ハッシュ法では、ある配列変数を使っており、インデックスがその配列番号となる。この配列変数をハッシュテーブルと呼ぶ。ここでは、ハッシュテーブルに、線型リストのヘッドを格納している。
Node heads[10];
配列変数のサイズを固定しないようにするには、次のようにする。
typedef struct{
int size;
Node *heads;
} Hash;
- - - - - -
Hash *h;
h = (Hash *)malloc(sizeof(Hash));
h->heads = (Node *)malloc(sizeof(Node)*size);
h->size = size;
※ 説明のため省略したが、h == NULL、h->heads == NULL の検査をすること。
ハッシュ操作の関数として、ハッシュテーブルの初期化、要素の登録、要素の検索のサブルーチンを作成せよ。
課題1および課題2を完成させよ。list.h, list.c, hash.h, hash.c, および Makefile を提出せよ。また、list1003.c の実行結果を提出せよ。
リスト操作、ハッシュ操作において、要素の削除を行うためのサブルーチンを追加せよ。たとえば、hash_remove(h, "ACCORD")、list_remove_by_key(l, "ACCORD") など。list.h/c や hash.h/c にコードを書き込み、宿題のなかに含めて提出せよ。なお、「追加課題」という印を書いておくこと。実行結果は、工夫してわかりやすく示すこと。たとえば、 list1004.c を参考にせよ。
2005.6.22 by tokuhisa