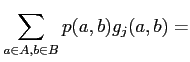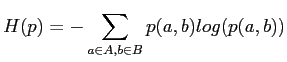Next: 素性 Up: 問題設定と提案手法 Previous: 提案手法 目次
最大エントロピー法とは,あらかじめ設定しておいた素性
![]() の集合を
の集合を ![]() とするとき,
式(3.1)を満足しながらエントロピーを意味する式(3.2)を最大にするときの確率分布
とするとき,
式(3.1)を満足しながらエントロピーを意味する式(3.2)を最大にするときの確率分布 ![]() を求め,
その確率分布にしたがって求まる各分類の確率のうち,
もっとも大きい確率値を持つ分類を求める分類とする方法である[5,6,7,8].
を求め,
その確率分布にしたがって求まる各分類の確率のうち,
もっとも大きい確率値を持つ分類を求める分類とする方法である[5,6,7,8].
ただし,![]() は分類と文脈の集合を意味し,
は分類と文脈の集合を意味し,![]() は 文脈
は 文脈 ![]() に素性
に素性 ![]() があってなおかつ分類が
があってなおかつ分類が ![]() の場合1となり,それ以外で0となる関数を意味する.また,
の場合1となり,それ以外で0となる関数を意味する.また,
![]() は,既知データでの
は,既知データでの ![]() の出現の割合を意味する.
の出現の割合を意味する.
式(3.1)は,確率 ![]() と出力と素性の組の出現を意味する関数
と出力と素性の組の出現を意味する関数 ![]() をかけることで 出力と素性の組の頻度の期待値を求めることになっており,右辺の既知データにおける期待値と,左辺の求める確率分布に基づいて計算される期待値が等しいことを制約として,エントロピー最大化(確率分布の平滑化)を行って,出力と文脈の確率分布を求めるものとなっている.
をかけることで 出力と素性の組の頻度の期待値を求めることになっており,右辺の既知データにおける期待値と,左辺の求める確率分布に基づいて計算される期待値が等しいことを制約として,エントロピー最大化(確率分布の平滑化)を行って,出力と文脈の確率分布を求めるものとなっている.