Next: 表の精度の向上に向けた課題 Up: 階層クラスタリングの最適な結果との比較 Previous: 階層クラスタリングの最適な結果との比較 目次
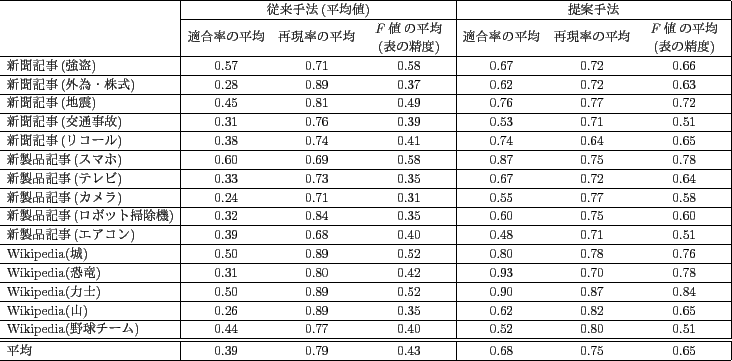
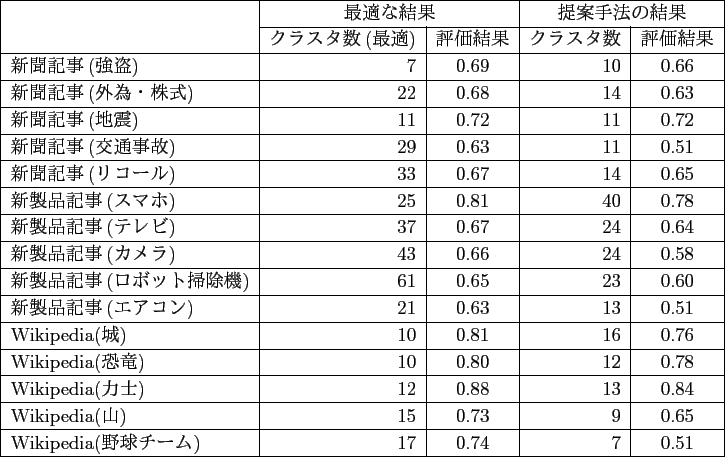
結果を見ると,新製品記事(ロボット掃除機)や新製品記事(カメラ),新聞記事(リコール)での推定されたクラスタ数が最適なクラスタ数に比べ非常に小さい値となっている. これらの複数文書は表5.5のように,いずれも正解の表に占める空欄の割合が多い. そのため,提案手法において表の埋まり具合を過度に考慮したことが悪く働き,このように推定されるクラスタ数が大幅に少なくなったと考えられる. この問題を解消するには,表の埋まり具合と表の密集度の重みを文書に応じて調整する必要がある. 具体的には複数文書の文書間の類似度を求めるなどして表の空欄の割合を推定し,これを基に表の埋まり具合と密集度の重みを調整することで,階層クラスタリングにおける最適なクラスタ数により近づくと考えられる.