クラスタリング結果には表3.1の(a)ように関連する文だけで構成される密集率の高いクラスタもあれば,表3.1の(b)のように関連性のない文で構成される密集率の低いクラスタもある.
密集率の高いクラスタは重要であると考えられる.
よって,![]() 番目のクラスタの密集率
番目のクラスタの密集率![]() を式3.1のように定める.
ここで,
を式3.1のように定める.
ここで,![]() は
は![]() 番目のクラスタに含まれる文の総数であり,
番目のクラスタに含まれる文の総数であり,![]() は
は![]() 番目のクラスタに含まれる
番目のクラスタに含まれる![]() 番目の文のベクトルであり,
番目の文のベクトルであり, ![]() は
は![]() 番目のクラスタに含まれる文のベクトルの平均である.
密集率の計算の例を図3.4に示す.
番目のクラスタに含まれる文のベクトルの平均である.
密集率の計算の例を図3.4に示す.
式3.1で求めたクラスタの密集率![]() を,式3.2を用いて,最小値が0,最大値が1になるように正規化する.
ここで,
を,式3.2を用いて,最小値が0,最大値が1になるように正規化する.
ここで,![]() は
は![]() 番目のクラスタの正規化されたクラスタの密集率であり,
番目のクラスタの正規化されたクラスタの密集率であり,![]() はクラスタの総数である.
はクラスタの総数である.
| (3.3) |
| (3.4) |
多くの文書の情報を含むクラスタほど重要であると考えられる.
よって,![]() 番目の文書カバー率
番目の文書カバー率![]() を式3.5のように定める.
を式3.5のように定める.
![]() は
は![]() 番目のクラスタにおいて文を抽出できた文書の数であり,
番目のクラスタにおいて文を抽出できた文書の数であり,![]() は文書の総数である.
は文書の総数である.
式3.5で求めた文書カバー率![]() を,式3.6を用いて,最小値が0,最大値が1になるように正規化する.
ここで,
を,式3.6を用いて,最小値が0,最大値が1になるように正規化する.
ここで,![]() は
は![]() 番目のクラスタの正規化された文書カバー率であり,
番目のクラスタの正規化された文書カバー率であり,![]() はクラスタの総数である
はクラスタの総数である
| (3.7) |
| (3.8) |
![]() 番目のクラスタの重要度
番目のクラスタの重要度![]() を式3.9のように定義する.
を式3.9のように定義する.
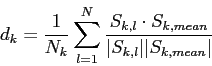
![\begin{table}
\begin{center}
\includegraphics[width=14cm]{cluster_accurancy.eps}
\end{center}
\end{table}](img14.png)
![\includegraphics[width=14cm]{accurancy.eps}](img15.png)