


Next: 場所名の解析
Up: 個別的な情報の抽出
Previous: 個別的な情報の抽出
目次
日本語固有表現の抽出における先行研究として福島らの研究がある[2].
福島らは大規模なウェブコーパスから固有名リストという形式で知識を収集し,
そのリストを素性として系列ラベリングのモデルに取り込むことで,固有表現抽
出の精度を向上させる手法を提案した.
固有表現抽出における精度の評価としてCRLデータセットを利用している.
固有名詞と数値表現を区別せずに計算した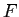 値において,89.20%とベースライン
の89.01%を0.28%上回っている.
値において,89.20%とベースライン
の89.01%を0.28%上回っている.
2013-02-23