概要
形態素解析では通常、固有名詞を一単語として扱う。しかし企業名は人名や地名、業種などをあらわす語から構成される場合が多い。これらの情報は音声変換における読み情報の付与や条件付き情報検索に必要である。そこで本研究では、統計的手法により企業名の単語分割を行った。結果として
trigramを適用した時最大正解率90.58%が得られ、企業名における統計的手法の有効性が示された。課題として、企業名特有の表記のゆれの扱いの工夫による正解率の向上がある。
1 はじめに
日本語の文章は通常、英語などの言語の場合と異なり、テキストに単語境界を表記せず、連続した文字で記述される。しかし機械翻訳などにおいて構文解析や意味解析を行なうには単語要素に分離されている必要があるため、形態素解析の品詞同定の前段階に単語境界の推定が行われる。その際、固有名詞は分解されず、通常ひとまとまりの単語として処理される。人名や地名を示す固有名詞は特定の対象物を直接指すため問題ないが、企業名の場合は人名、地名、業種などの複数の単語要素から構成されることが多い。これらの単語要素は、日本語音声変換におけるアクセントやイントネーションなどの読み情報の制御や、条件付き情報検索に必要な情報の抽出に役立つ情報である。そこで本研究では、企業名に含まれる情報の抽出の第一段階ともいえる企業名の単語分割を試みた。なお、本研究における企業名とは、会社、商店など、営利目的の組織一般の名称を指す。
単語分割に関し提案されている主な方法は、単語辞書と単語接続規則を参照する方法と、文字連鎖確率を用いる統計的手法の二種類である。企業名の場合、未知語が多く含まれると考えられるので、本研究では未知語にも対応が可能である統計的手法を採用した。
統計的手法において文字連鎖確率を求めるためには、大量の学習済みデータを必要とする。単語境界の推定を行う場合、大量の単語境界情報の付与されたデータが必要である。しかし企業名の場合、統計処理に十分な規模かつ単語境界情報の付与されたデータベースが存在しなかったため、統計的手法による単語境界の推定は不可能であった。つまり企業名に自動解析を適用した場合の精度が明らかにされていなかった。
しかし最近になり、
NTT-ATが800万件を越える規模かつ単語境界情報の付与された日本企業名データベースが作成されて使用可能となったため、統計的手法による単語境界の推定を行なう環境が整った。本稿では、この日本企業名データベースを利用して統計的性質を調べ、単語境界位置の自動推定を試みた。
2 単語分割の手法
単語境界を統計的に推定する方法の一つに、
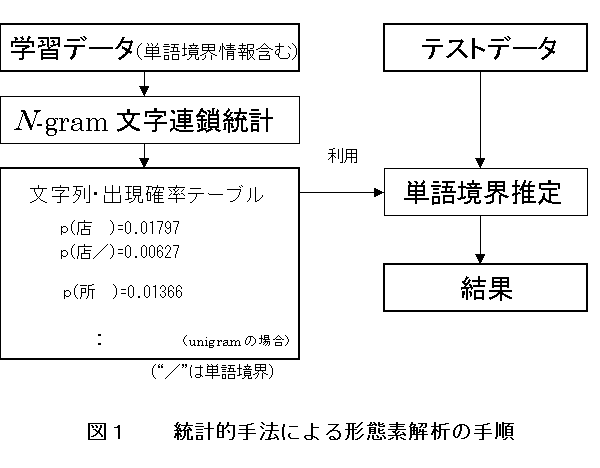
N重マルコフ文字連鎖モデルを適用し、文字連鎖確率がある閾値より小さい箇所を単語境界とする方法があるが、精度の良い閾値の決定が難しいという問題点がある。そこで本稿では、あらかじめ単語境界の付与された企業名データ(学習済みのデータ)から文字連鎖確率を計算し、それを使用して与えられた企業名の単語境界を推定するという方法を取る。処理の流れを図1に示す。
まず単語境界情報の付与された大量の学習データを用意し、各データについて
N-gram文字連鎖統計を取る。出力としてN文字からなる文字列とその遷移確率が得られる。図1の文字列・出現確率テーブルはunigramの例であるが、同じ文字列“店”の後に単語境界が続く場合(p(店/))と続かない場合(p(店))二通りの出現確率が得られる。テストデータについて学習データを利用することで単語境界を推定し、最もらしい位置に単語境界を付与した結果が得られる。
2.2
N-gram文字連鎖統計
単語境界情報を得るためには、文字列の出現確率を調べておく必要がある。本稿では、文字連鎖による統計的性質を表す代表的な手法の
N-gram文字連鎖統計を使用した。N-gram文字連鎖統計では、入力文字列中の任意のN文字が連続する断片的な文字列の出現頻度から、出現確率を求められる。N
は自然数であり、特にN=1の場合をunigram、N=2をbigram、N=3をtrigramと呼ぶ。unigramは文字の出現確率の積、bigramは前の文字と次の文字の遷移確率の積、trigramは2文字前と1文字前を考慮した遷移確率の積となり、それぞれ(1.1)式、(1.2)式、(1.3)式で表す。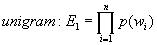
(1.1)
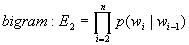
(1.2)
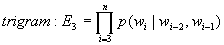
(1.3)
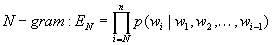 一般に
一般に
(2)
Nを大きく設定することで長い単語の統計も確実に行えるが、作業に必要な時間や計算量も多く必要となる。本稿では1≦N≦6の範囲を対象とした。
2.3
単語境界推定の方法
まず単語境界の付与された学習済みの企業名データを対象に、
N文字連鎖すべてについて出現確率を求める。いま、与えられた企業名の文字列を
c1c2…cnとする。i(=1,2,…,n)番目の文字ciの直後に単語境界が存在する場合をci/と表すことにする。ここでwi={ciまたはci/} (3)
と置くと、全ての
wiに対して条件付き確率![]()
(4)
は、単語境界付きデータベースから統計的に求めることができる。そこで各
wiに対してciまたはci/を選択し、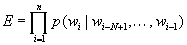
(5)
の値を最大にする
wi(i=1,2,…,n)の組を求める。このとき単語境界は、wi=ci/となるwiの直後に存在する。
実際に全ての
wi(i=1,2,…,n)について展開すると、テストデータの長さが1文字増えるごとに二倍の計算量となり時間がかかる。よって何らかの方法で高速化を図る必要がある。例として
bigramの場合を考える。単語境界の推定には、図2のモデルを適用することができる。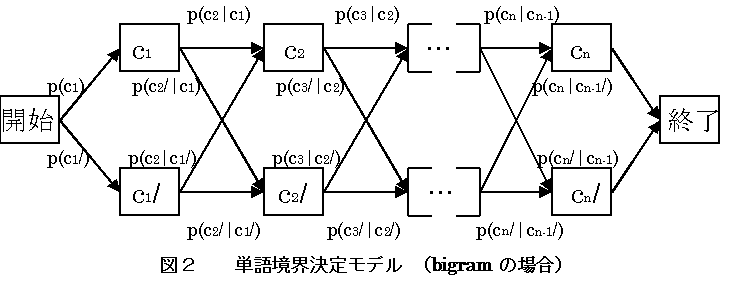
経路の条件付き確率の積を求める問題は、最短経路の選択問題に置き換えられる。よって、動的プログラミング法である
Viterbiのアルゴリズムを使用して解くことができる。Viterbi
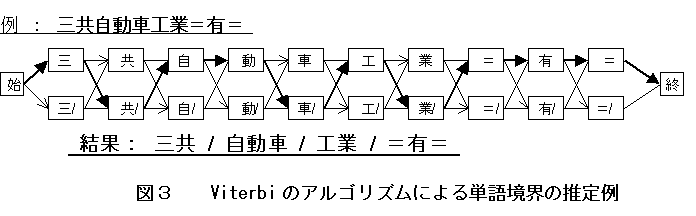
のアルゴリズムでは次のように処理される。先頭から順に走査し、文字wiを決定したい時、確定済み文字列w1w2…wi-1に続きやすい文字wiをciとci/から選び確定する。この作業を文字列の最後まで行うことで全てのwiを決定する。具体例の一つとして、
bigramの場合の実行例を図3に示す。図2に較べて経路の数が半分に減ることで反復回数が押さえられ、大幅に計算量が削減されることがわかる。
2.5
単語境界の推定結果の検証
テストデータは本来学習データと同一のデータベースから作成された。したがってテストデータには単語境界情報が付与されている。このため単語境界の推定を行う前に、単語境界情報を除去する必要がある。得られた単語境界情報を含む結果の正誤判断は、得られた単語境界情報と除去する前の単語境界情報との比較により行った。評価式を
(6)式に示す。![]()
(6)
3.1
実験の対象
本稿で対象とする日本語企業名データベースは、
NTTアドバンスドテクノロジ(株)が電話帳データベースの企業名を基に、人手で単語境界などの情報を付加したものである。本稿で利用したデータは、企業名およびその単語境界位置情報である。データベースの中から信頼度の低いと思われるデータ約11,000件を自動あるいは手動で削除し、残る6,411,910件を実験に使用した。オープンテストを実施するため、10,000件ランダムに抽出したデータを正解率計算用のテスト用サンプルデータ、残りの6,401,910件をN-gram文字連鎖統計用の学習データとして使用した。
3.1
節の学習データにて実験を行ったところ、表1および図4の結果が得られた。
表1 単語分割の正解率
|
N |
1 |
2 |
3 |
4 |
5 |
6 |
|
正解率 [%] |
62.11 |
82.82 |
90.58 |
87.63 |
78.04 |
62.02 |
図4 単語分割の正解率
表1から、trigram時に最大確率90.58%を得られる。unigramでは文字遷移確率の影響を受けないため62.11%に留まった。4-gram以上では次第に正解率が低下する。
実験の結果、
trigram時に90.58%の最大正解率を得た。しかしNがさらに大きくなると正解率が大きく低下する結果となった。N-gram文字連鎖統計では理論上、正解率は上昇を続けるはずである。このような結果になった原因を明らかにするため、実際のデータを基に成功例と失敗例を分析する。
(a)正常に単語境界の推定が行える場合
(結果)丸山/燃料/商会/矢作/製作/所
(正解)丸山/燃料/商会/矢作/製作/所
一般的に用いられる熟語が多く、人名や地名も一般的であるため、全ての単語において高い文字連鎖確率が得られる。単語境界の推定に失敗する要素は特に無いため、正しい結果が得られる。
(b)まとめてもよいが成功とみなされる場合
(結果)伊藤/文房/具/店
(正解)伊藤/文房/具/店
一般的な単語が多い点で
(a)に近いが、“文房具”は“文房/具”と単語境界が挿入されるが、“文房具”を一語として扱う方が一般的である。。これはデーターベースの単語境界情報が音声処理の分野での利用を考慮して設計されているためであり、発音境界として挿入されているためと考えられる。実際全ての“文房具”は“文房/具”と分けられており、同様な例は多数ある。よってデータベースの方針に従い、正解とした。
4.2 失敗例
(c)非常に稀な用例
(結果)古/美術私楽
(正解)古美術/私楽
“術私”“私楽”間はいずれも文字共起確率がゼロである。しかし正解では“術
/私”“私楽”となっており、単語境界の推定は確実に失敗する。学習データベースに表れにくい文字列ほど単語境界の推定に失敗する傾向がある。学習による文字連鎖確率が得られないという理由から、本手法における単語境界の推定が不可能となる。誤った文字列の共起確率が偶然により高くなる可能性も増す。
(d)境界付近が単語に一致するため共起関係が逆転する場合
(結果)釜石/下/水道/管理/作業/所
(正解)釜石/下水/道/管理/作業/所
境界を跨ぐ文字列“水道”が単語に一致し共起確率が高くなり、“下水”の部分の共起確率を大きく凌ぐため、単語境界の位置が変わる。“下水道”は一語とみなしても問題無いと思われるが、
(b)と同様の理由により単語境界が挿入される。上記の例のような単語境界位置の移動の他、単語境界の抜け落ちも同様の理由により発生する。
4.3 失敗の原因の考察
失敗の主な原因は、
4.2節(c)に示される単語の学習データにおける出現頻度の落ち込みである。データベースの全データを対象に検証したところ、文字共起確率が全く得られない場合、単語境界の挿入されない場合が86.9%を占める。これは判断の付かない場合単語境界を入れない方が正解に近いことを示す。また、学習データ中における出現頻度が2以下となる文字列は全体の16.2%に及ぶため、これが失敗の最大の原因と考えられる。特にNを大きくした時にこの傾向が顕著となる。十分な数のデータにも関わらず出現頻度が上がらない理由は、企業名特有の表記ゆれである。同じ意味でありながら表記の異なる例を
図5に示す。
(例1)株式会社 (株) =株= corp. (c)
(例2)クラブ 倶楽部 くらぶ
(例3)国 國
図5 同じ意味を持つ語の例
本研究ではデータベース内の符号や一部の特殊な文字列を除き、直接文字情報を処理した。このため
図5に示されるような各文字列は別扱いであるため、この影響で頻度が得られない場合がある。対策としては同じ対象を示す語をまとめる手法が考えられる。これはテーブルを作成しデータベースの内容を置換するクラスタリングにより可能となるが、実際は固有名詞特有の問題を考慮する必要がある。企業名は、表記そのもので登記されている場合も多いため、同様の表記を全て統一することはできない。企業名に多い表記ゆれの扱いを考慮することで、失敗を大きく押さえることが可能と考えられる。
5 結論
本稿では、企業名に統計的手法を適用して単語境界の推定を試みた。単語境界情報を含む日本企業名データベースを利用し、約
640万件を学習データとしてN-gram統計を実行して文字連鎖確率を取得した上で、単語境界情報を仮除去した1万件のサンプルデータを対象に単語境界の挿入を実施し、結果について検証した。その結果としてtrigramを適用した場合に90.58%の最大正解率で正しく単語境界の推定が可能であることが示された。よって企業名の場合にも一般の複合名詞の場合と同程度、統計的手法における単語境界情報の挿入が有効であることが判った。
本実験では、定型的な語についてクラスタリングを行なっていない。このため意味の同じ文字列についての出現確率の分散が起こり、失敗の大きな原因となっている。正解率をさらに向上させるためには、必要な文字情報についてのクラスタリング操作が必要となる。しかし企業名は固有名詞であり、表記そのものが意味を持つ場合も多いため、適切なクラスタリングが必要と思われる。今後は表記のばらつきに対処しまとめる方法について考慮する必要がある。
参考文献