


汎化の対象となる意味属性の選択方法としては、意味属性の粒度に注目して、意味の粒度が細かい、最下位の意味属性から順次、選択する方法、また、意味属性の重みに注目し、検索にあまり寄与しないと思われる重みの少ない意味属性を選択する方法が考えられる。 図2に具体的な汎化の例を示す。
文書DB内に収録された文書が検索対象となる確率はすべて等しいとし、文書DB内、すべての文書を対象に求めた特性ベクトルの和をVt(式5)とする。
Vtの要素niの値が小さい意味属性は検索精度に与える影響が少なくなるから、少ない基底数で高い検索精度を得るには、各niの値が均等していることが必要である。
つまり、各niの値が均等になるように意味属性を選択し、汎化すれば、検索に寄与しない意味属性を順次削減することが期待できる。
| (7) | |||
| niは意味属性iの文書DB内の出現頻度 |
| H | = | ||
| = | 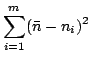 |
(8) |
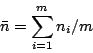 |
(9) |
| H-H' | = | (10) | |
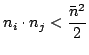 |
(11) |