


Next: おわりに
Up: 従来法との比較実験
Previous: 検索精度に関する実験
単語ベクトル空間法(最大基底数5,000)と前節で説明した粒度の汎化と重みの汎化による基底削減法を適用した意味ベクトル空間法の基底数と検索精度の関係を求め、基底数削減の可能性と必要最小限の基底数について比較する。
図4に基底数と検索精度(F値)の関係を示す。
また、検索精度の低下の許容範囲を10〜20%程度とした場合の必要最小限の基底数を表2に示す。
Table:
必要最小限の基底数
| 方式種別 |
基底数削法 |
検索精度低下の許容度 |
| |
|
ピーク値の |
ピーク値の |
| |
|
10% |
20% |
| 本手法 |
粒度による汎化 |
700属性 |
500属性 |
| |
重みによる汎化 |
300属性 |
200属性 |
| 従来法 |
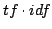 法 法 |
2,500属性 |
1,500属性 |
以上の図4、表2の結果から、以下のことが分かる。
- (1)
- 意味ベクトル空間法は、従来の単語ベクトル空間法に比べて、基底数削減に強い。
- (2)
- 汎化の方法は、粒度による汎化より重みによる汎化の方がより基底数削減に強い。
- (3)
- 基底数が約2,500種以下では、検索精度は意味ベクトル空間法の方が優れている。
必要最小限の基底数については、検索精度の低下の許容範囲を10〜20%程度とすると必要最小限の基底数は1500〜2000種である。これに対し、本方式は約200〜300種程度まで基底数を削減できることがわかる。
2000-05-30